Setting up the AI multi-agents for evaluations
Lighthouz is the first platform to create your own bespoke AI multi-agents to do AI evaluations, in just 1 minute!
The Lighthouz platform enables:
- Creating AI evaluation agents and AI meta-evaluation agents
- Creating evaluation criteria
- Providing evaluation samples to seed the evaluation agents
- With a user-friendly interface, you can provide feedback to the AI agents.
A hierarchical AI multi-agent architecture
You can create a hierarchical multi-agent architecture with two or more evaluation AI agents and one meta evaluation AI agent. You can add more evaluation agents, or remove to only keep one evaluation agent. There is only one AI meta-evaluation agent.
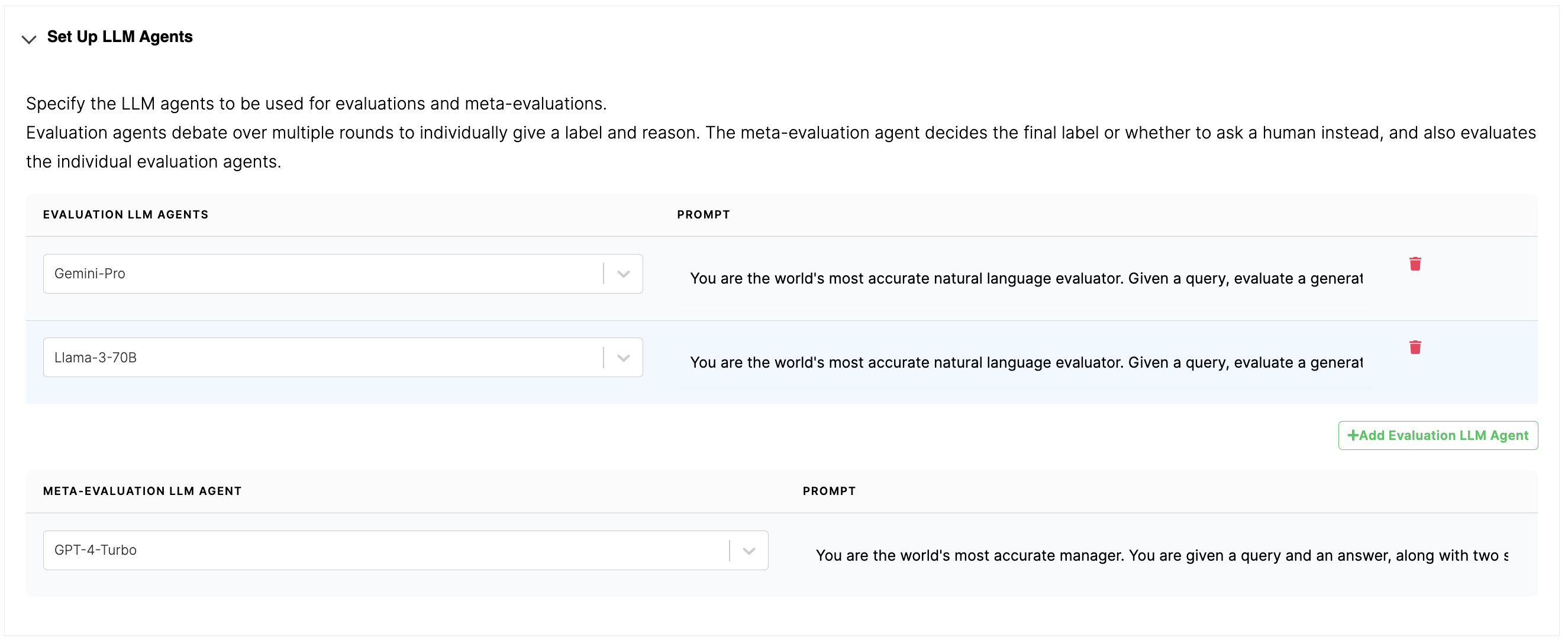
Setting up the evaluation agents
To set up your agents, you select the LLM and define its prompt. The Lighthouz framework takes care of the rest — the multi-round discussion between agents, the coordination with the meta-evaluation agent, and incorporating the human feedback.
The initial prompt you provide in this step is used in the initial as well as the discussion rounds, as described below.
Evaluation agent’s prompt information in the first round is:
The default initial prompt for the agents is the following:
You are the world's most accurate natural language evaluator. Given a query, evaluate a generated answer compared to the correct answer.
This gets augmented with the category information, evaluation examples, and data to be evaluated. The resulting evaluation prompt for each evaluation is:
{initial_prompt}
## The category definitions are:
{category_prompt}
The output category should only be one of the above categories. You must generate an output. You can not output 'I don't know', 'there is no information', etc.
You should output the reasoning behind the output labels as well. Only output in JSON format provided below.
## OUTPUT
{{
"label": "$category",
"reasoning": "$reasoning"
}}
{example_prompt}
# Use the following information to provide an output category:
"Query": "{query}",
"Correct answer": "{ground_truth}",
"Generated answer": "{retrieved_answer}",
### Output:
Evaluation agent’s prompt information in the discussion rounds is:
In the discussion rounds, the information of the agent’s own output from the previous round as well as the outputs of the other agents are included in the prompt.
The discussion round prompt for each evaluator is:
{initial_prompt}
## The category definitions are:
{category_prompt}
The output category should only be one of the above categories. You must generate an output. You can not output 'I don't know', 'there is no information', etc.
You should output the reasoning behind the output labels as well. Only output in JSON format provided below.
## OUTPUT
{{
"label": "$category",
"reasoning": "$reasoning"
}}
## DISCUSSION
Your previous output category and reasoning was:
{previous_output}
The output category and reasoning by other evaluators are as follows:
{opinions}
# Review your own previous output category and reasoning as well as other opinions. Then decide the output category and reasoning.
# Use the following information to provide an output in JSON format:
"Query": "{query}",
"Correct answer": "{ground_truth}",
"Generated answer": "{retrieved_answer}",
# Output:
Setting up the meta-evaluation agent
Similar to the evaluation agents, we can set up meta-evaluation agents by selecting the LLM and providing an initial meta prompt. The default values are given below.
Meta evaluation agent’s prompt information is:
The default meta-evaluation prompt is
You are the world's most accurate manager. You are given a query and an answer, along with two sets of evaluation labels and reasons. Your job is to assign a final label to the query based on the labels given. The output category should only be one of the 4 categories. You must generate an output. You can not output 'I don't know', 'there is no information', etc. You should output the reasoning behind the output labels as well.
This is augmented with the category information, the outputs of the individual evaluators, example outputs, and the data to evaluate.
The complete prompt becomes:
{initial_master_prompt}
## The category definitions are:
{category_prompt}
For your reference output category and reasoning by other evaluators are as follows:
{opinions}
## OUTPUT
{{
"label": $category,
"reasoning": $reasoning
}}
{example_prompt}
# Use the following information to provide an output category:
"Query": "{query}",
"Correct answer": "{ground_truth}",
"Generated answer": "{retrieved_answer}",
### Output:
Next, we will set up the evaluation criteria.
Setting up the semantic evaluation criteria
The power of agents is to conduct semantic evaluations that require complex reasoning and content understanding. For example, rating the correctness, completeness, helpfulness, creativity, etc.
To set up the evaluation criteria, you need to provide category labels and definitions (i.e., instructions) that describe the level of each category.
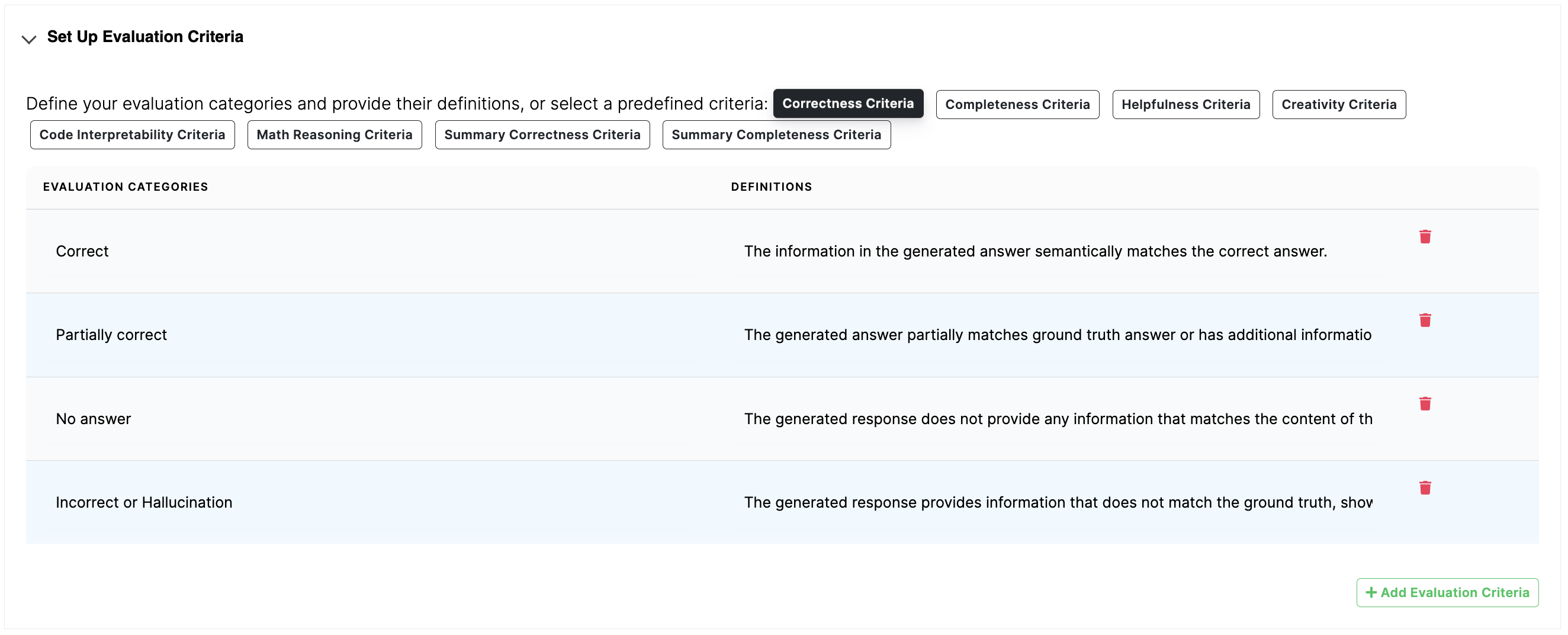
We provide a few evaluation criteria templates, such as answer correctness, answer completeness, helpfulness, creativity, code interpretability, math reasoning, summary correctness, and summary completeness.
The detailed description of these supported evaluation criteria are given in the Section on Evaluation Criteria.
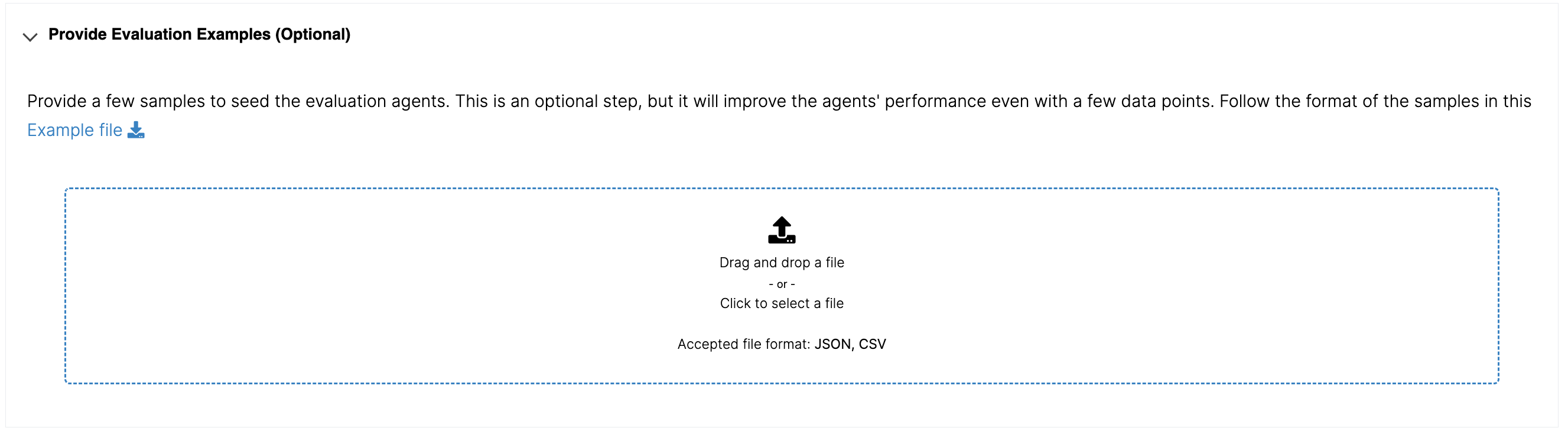
Providing evaluation examples (optional step)
You can provide examples of labeling per evaluation category. This seed the agents to learn to mimic human evaluation behavior from the get-go. At least two examples per evaluation category is recommended. This is an optional step.
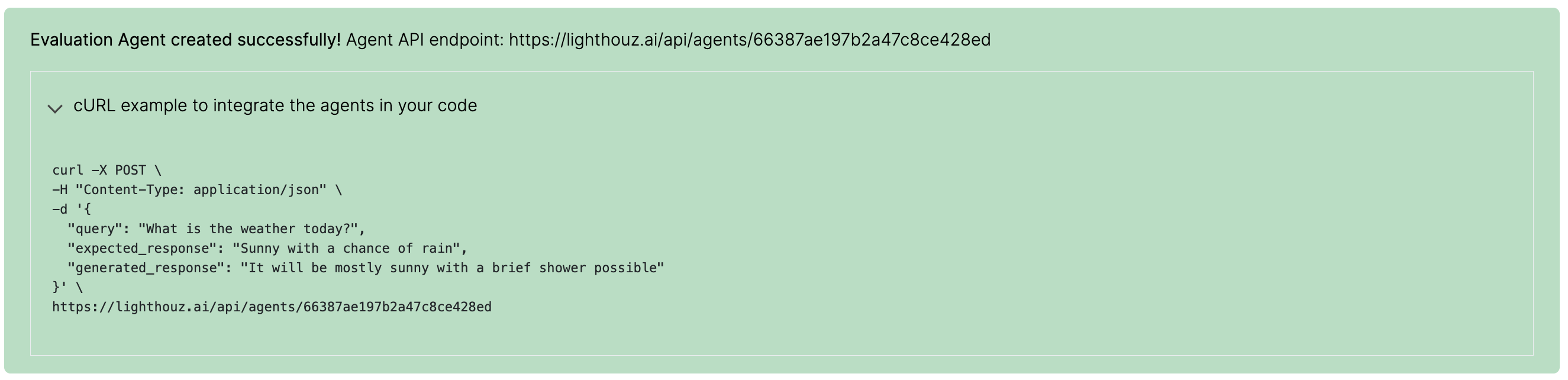
Outcome: Agent API endpoints
The agents are now ready to go! Each evaluation multi-agent is assigned a unique API endpoint. The API is useful for future external usage and integration into user code.