New RAG Benchmark for Finance applications: Apple 10K 2022

We are excited to release a new RAG benchmark for finance applications. This dataset contains queries and responses to evaluate AI chatbots and RAG applications for hallucinations and accuracy. The dataset was created using Lighthouz AutoBench, a no-code test case generator for LLM use cases, and then manually verified by two human annotators.
The dataset is available on HuggingFace at: https://huggingface.co/datasets/lighthouzai/rag-benchmark-finance-apple-10K-2022.
The dataset is also preloaded on all Lighthouz accounts.
Dataset Details
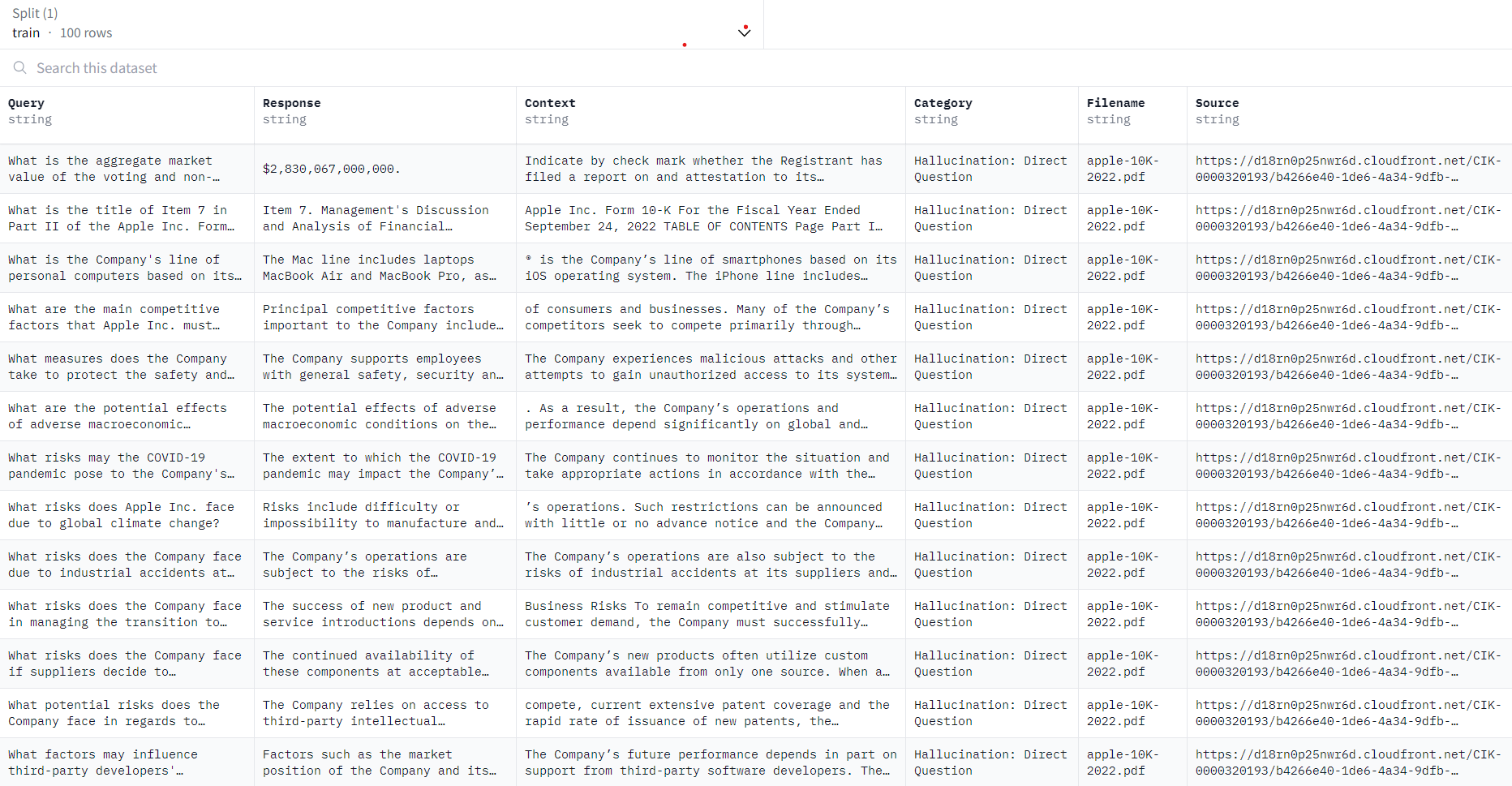
This dataset was created using Apple's 10K SEC filing from 2022. It has 100 test cases, each with a query and a response. Each row in the dataset represents a test case consisting:
- Query: This the input prompt.
- Golden expected response: This is the correct answer for the prompt.
- Context: This is the context from which the prompt and golden response are generated.
- Category: This defines the test category, as per Lighthouz taxonomy. This is set to Hallucination: Direct Questions in this dataset.
- Filename: This is the file from which the test case has been created
- Source: This is the URL from which the file was downloaded.
Uses
This dataset can be used to evaluate AI chatbots and RAG applications for hallucations and response accuracy. This dataset can be used with any LLM evaluation tool, including Lighthouz Eval Studio.
When evaluating LLM responses for hallucinations, Lighthouz Eval Studio provides evaluation metrics and classifies responses into the following categories:
- Correct and complete
- Correct but incomplete
- Correct and extra information
- Hallucinations or Incorrect
- No Answer
How was the dataset created?
The dataset was created using Lighthouz AutoBench, a no-code test case generator for LLM use cases, and then manually verified by two human annotators.
Lighthouz AutoBench is the first no-code test case generation system that is trained to generate custom task-specific benchmarks. AutoBench supports benchmark generation capabilities to evaluate AI chatbots for hallucinations, Off-topic responses, Prompt Injection, and PII leaks.
More information on Lighthouz AutoBench can be found at https://lighthouz.ai.
Contact information
For questions about the dataset, you can message team@lighthouz.ai.